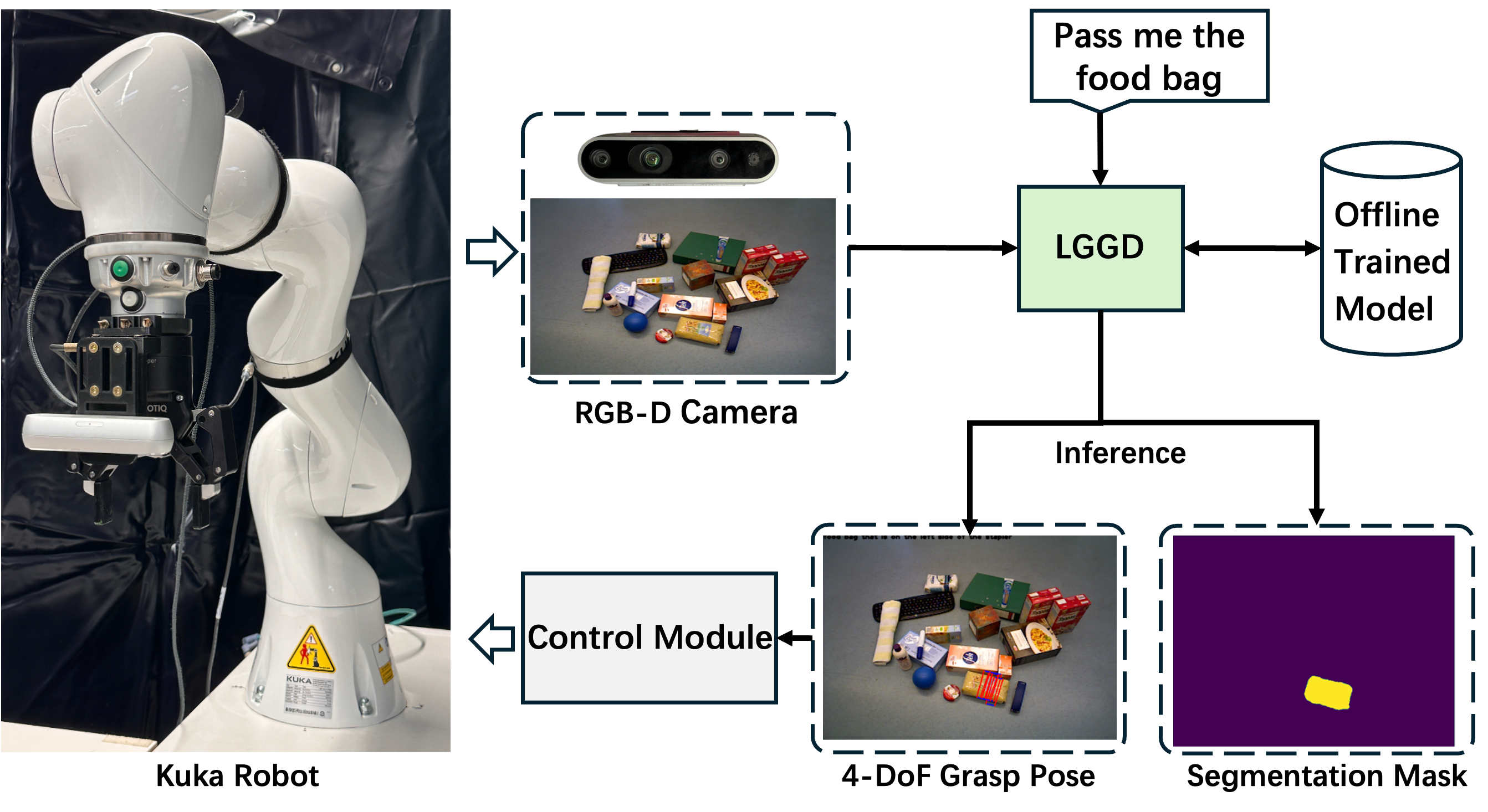
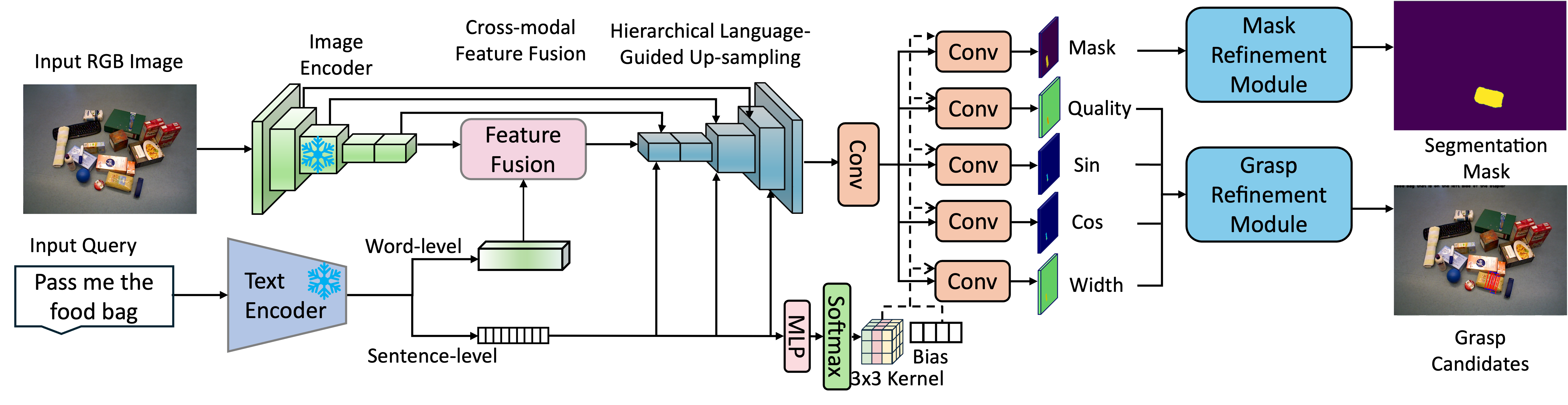
Grasping is one of the most fundamental challenging capabilities in robotic manipulation, especially in unstructured, cluttered, and semantically diverse environments. Recent researches have increasingly explored language-guided manipulation, where robots not only perceive the scene but also interpret task-relevant natural language instructions. However, existing language-conditioned grasping methods typically rely on shallow fusion strategies, leading to limited semantic grounding and weak alignment between linguistic intent and visual grasp reasoning. In this work, we propose Language-Guided Grasp Detection (LGGD) with a coarse-to-fine learning paradigm for robotic manipulation. LGGD leverages CLIP-based visual and textual embeddings within a hierarchical cross-modal fusion pipeline, progressively injecting linguistic cues into the visual feature reconstruction process. This design enables fine-grained visual-semantic alignment and improves the feasibility of the predicted grasps with respect to task instructions. In addition, we introduce a language-conditioned dynamic convolution head (LDCH) that mixes multiple convolution experts based on sentence-level features, enabling instruction-adaptive coarse mask and grasp predictions. A final refinement module further enhances grasp consistency and robustness in complex scenes. Experiments on the OCID-VLG and Grasp-Anything++ datasets show that LGGD surpasses existing language-guided grasping methods, exhibiting strong generalization to unseen objects and diverse language queries. Moreover, deployment on a real robotic platform demonstrates the practical effectiveness of our approach in executing accurate, instruction-conditioned grasp actions. The code will be soon released publicly.